append 函数暴走导致服务进程被系统杀掉
此篇中是 9 月中的事情,今天才补充变成完整版发布。
问题表象
患者:我们 BI 体系的一个计算服务,用 Go 写的,且称为 Calc 服务。
症状:最近在我们跑一个计算量大的 API 时,Calc 服务总是被 Supervisor 重启。
定位大致原因
看日志,有不少 map 并发读写的 panic:1
fatal error: concurrent map read and map write
这个以前是小概率事件,猜测可能是最近数据量大了,概率变高了。赶紧加读写锁修复之。上线后,panic 日志没了,服务却依然频繁被重启。
可 Calc 服务没有其他错误日志了,不好定位问题了。那就试试 Supervisor 的日志,查查它有没有记录它重启我们服务的理由。
在配置文件 /etc/supervisord.conf 里查到日志路径 /tmp/supervisord.log,发现了很多如下配对日志,且每隔几分钟就有:1
2INFO exited: bi-calc (terminated by SIGKILL; not expected)
INFO spawned: 'bi-calc' with pid 2629
看到基本都是因为收到 SIGKILL 信号而退出的。(后边的重启是我们启用的的 Supervisor 的自动重启功能)。我们自己不可能每隔几分钟就去杀服务,也没有雇佣其他的程序来干这票反复刺杀的事情。应该是操作系统干的,这时根据经验,我推测很可能是触发了 Linux 的 Out of Memory(OOM) Killer 机制了。
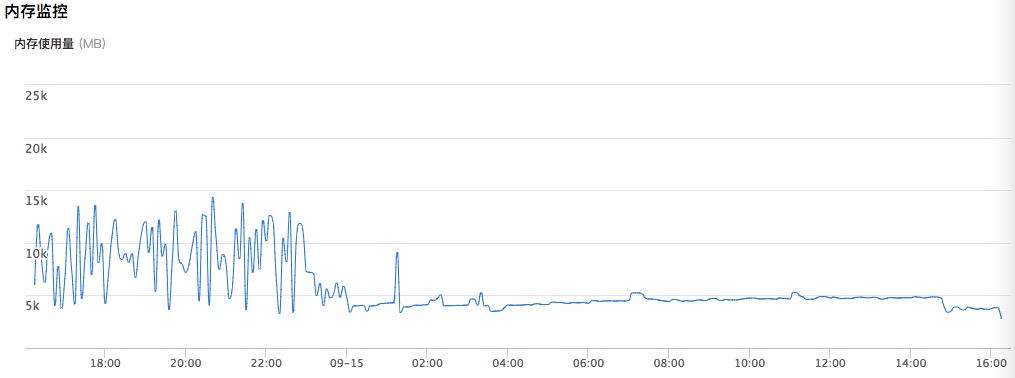
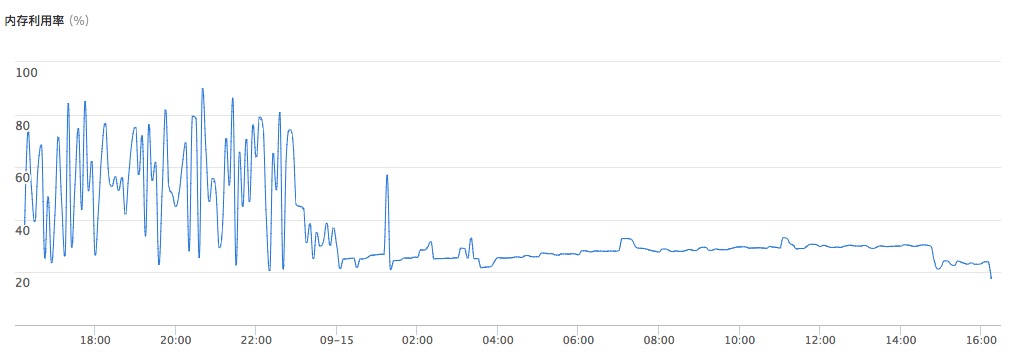
验证这个,看机器监控,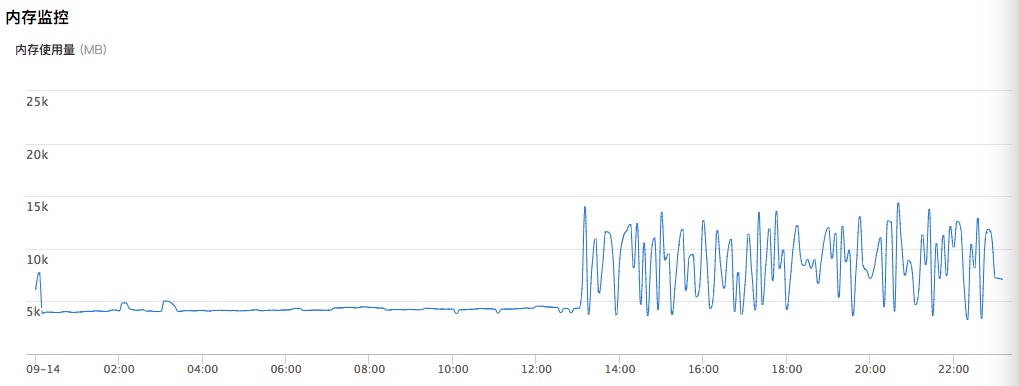
看到下午与晚上,内存确实一直占用很高,但感觉一直只是占用一会儿就下去了,紧凑波浪行。所以还不敢完全确认是 OOM,但我记得 OOM 有系统级日志的,然后在 /var/log/messages 里找到很多这个:1
Out of memory: Kill process 6769 (bi-calc) score 751 or sacrifice child
但要发现这个日志都是前今天的,症状相符,就是时间不对。进一步发现是这个系统日志文件已经停更 1、2 天了。突然想到,是不是记系统日志的服务宕机了?重启了下 syslogd 系统服务,然后如下命令坐等期望的日志出现:1
tail -f /var/log/messages | grep 'Out of memory'
然后每过几分钟,如愿刷一条 OOM 日志。此时,基本确定就是内存的问题。至于监控里那个波形也好解释了,冲到很大内存时被系统 Kill 掉,内存使用量自然就又回落了。如此规律,是因为篇头说的 API,我们有定时任务每隔几分钟跑一次。
分析具体原因
定位是内存原因后,开始我们怀疑是线上的 Go 版本只有 1.6.2,GC 跟不上导致的。更新到 1.9 后,问题依旧。
然后开始用 Go 自带的 pprof 来生成内存数据分析的图,感觉还不过瘾,然后用 go-torch 来生成函数占比的火焰图。马上定位到了暴涨函数。(不得不再安利下,Go 真是门工程语言啊,自带实用性能分析工具。当然这是他自带的如果工程工具之一。)
问题函数里的问题逻辑是:一个大循环里一直给往 slice 里 append 数据。大家去看看 slice 的内存扩展原理就知道原因了。
解决
查出原因就很好解决了,涉及到业务就不说了。
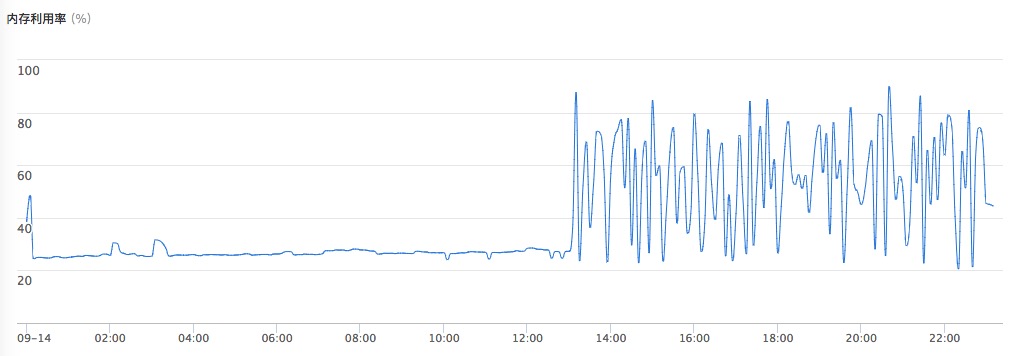
解决后的内存监控就优美了: