公司内网访问某业务系统经常卡
问题表象
患者:我们自己开发的一个工具系统,上边是很多提高开发效率的工具,且称为 B 系统。
症状:我们的 B 系统从某段时间开始经常卡顿,经常打开页面需要 20-60 秒左右才显示出来。基本没法使用。
追查 1 - 本地开发环境与线上都卡
线上服务卡顿比较严重后,我们发现本地开发环境也很卡。暗喜,这种情况就好办,能在本地开发环境把问题调试出来。
发现出规律,卡的页面,基本都是响应时间高达 1 分钟左右,而且不是单一页面才出现这种情况。所以不是某个业务模块的个别逻辑问题,而应该是一个通用的大家都调用的基础模块的问题。按步骤调试后就很轻松的发现,系统 B 的每个页面都会向一个统计系统发送页面被访问的信息(分析 B 系统的功能被使用情况的)。
这是一个 Http 的 Post 发送,并且是同步的方式发送。当时正好统计服务内部出现了问题,导致我们这个 Http 请求卡住直至超时返回。而这个超时默认的 1 分钟。
发现了这个就很好改了,将这个 Http 请求放到一个异步的 Go 协程里去做。这样 Http 请求出问题,不会影响 B 系统自己的业务逻辑。另外这个 1 分钟的超时也太长了,当 B 系统与统计服务之间出问题时,我们 B 系统会堆积大量的这个 Http 请求的协程,占用很多资源。所以同时将这个超时时间改为了 5 秒。
这个优化完成后,本地开发快如闪电。但是,发布到线上,改善了一些,但还是经常性卡顿,只是卡的时间短点儿。继续查。
追查 2 - 某逻辑里瞬间并发执行很多 SQL 更新
然后怀疑,是否因为某逻辑里瞬间并发执行很多 SQL 更新,导致其他页面请不到 SQL 执行资源。
基于此,查了数据库后台的监控,发现并没有太多的 InnoDB 锁等待。数据库各项指标也正常。伤感的同时,还是把这块先优化了看看。结果果然没起啥作用。
追查 3 - 系统 B 被 IT 单独限流了吗
继续追查,了解到,B 的服务器上其他业务系统,内网访问也慢,而我们其他服务器上的服务,内网访问没有这个问题。同时,我们访问例如百度之类的外部网站并不卡。所以初步怀疑,是不是运维给我们这个 B 服务器的 IP 做了访问限流(可能是误配置)。
与此同时,我拿起 Chrome 开发者工具,看控制台怎么报的时间消耗。如我所料,B 系统没有引用国外网站的链接,所以不是这个问题。但有收获,发现时间基本被消耗在 Initial connection 里。基本只要卡时,都是消耗在这个阶段。查资料,这个是建立 Socket 连接的三次握手阶段。
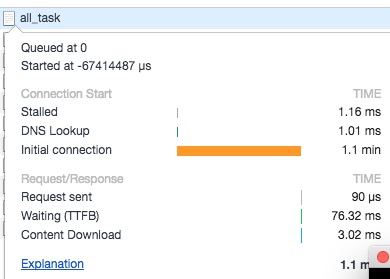
同时我们发现用手机 4G 访问 B 服务,很流畅,而且几位同学纷纷表示在家里访问我们 B 服务时,也是快如闪电。这样我们就越来越怀疑是公司内网主动或者被动的对这个网站的访问做了限制。把问题反馈给运维同学,但是他们说没有发现什么问题。
追查 4 - tcp_tw_recycle 与 NAT
继续追查,试了 traceroute 也没发现链路有什么问题。
然后想起前几天查一个服务内存泄露问题,在 /var/log/messages 里发现每 5 分钟有个 SYN 攻击日志。当时忙别的,没有继续追查。抱着试试看的心态,继续从这里深入下。
翻这个系统日志文件,找到日志:1
possible SYN flooding on port 80. Sending cookies.
搜索说是 net.ipv4.tcp_max_syn_backlog 配置的少导致的。同时把我引向了内核配置文件 /etc/sysctl.conf ,最简单的办法就是对比正常服务器和异常服务器的配置差异。于是,我将 B 系统的机器与另一个访问不卡的机器做对比,发现只差一个配置 net.ipv4.tcp_tw_recycle,B 机器上这个值配置的 1,而另外这个是 0 。虎躯一震,感觉快发现宝藏了。
继续查,果然,资料显示这个选项可以快速回收 TIME-WAIT 状态的连接,但是会影响 NAT 网络状态下的客户端连接(具体原理这里不转述了),刚好大家是只在公司内网情况下才有这个卡的问题,对应上了。将配置改为 0 后,不卡了。
下边的命令使上边的修改立即生效:1
# sysctl -p
其他
另外关于 TIME-WAIT,命令1
# netstat -ant | awk '/^tcp/{print $NF}' | sort | uniq -c | sort -nr
看连接状态统计:1
2
3
4
5
62386 TIME_WAIT
1880 ESTABLISHED
15 LISTEN
15 CLOSE_WAIT
2 FIN_WAIT2
1 LAST_ACK
对比了两个服务器,配置为 1 的服务器的 TIME-WAIT 确实比 0 的 要少很多。把 B 的机器改为 1 后,也确实这个状态的数量上去了。
